جنگل تصادفی چیست؟جنگل تصادفی یک تکنیک یادگیری ماشینی است
که برای حل مشکلات رگرسیون و طبقهبندی استفاده میشود و برای این کار از یادگیری گروهی استفاده میکند. یادگیری گروهی تکنیکی است که بسیاری از طبقهبندیکنندگان، برای ارائهی راه حلهایی برای مسائل پیچیده از آن استفاده میکنند.
توضیحاتی برای آشنایی با جنگلهای تصادفی
در بخش قبلی به صورت خلاصه به سوال جنگل تصادفی چیست؟ پاسخ دادیم. حال در این بخش به توضیحات بیشتری از این مفهوم میپردازیم. جنگلهای تصادفی تقریبا همان فراپارامترهای درخت تصمیم یا طبقهبندی کننده کیسها هستند. اما خوشبختانه، نیازی به ترکیب درخت تصمیم با یک طبقهبندی کننده کیسها نیست؛ زیرا به راحتی میتوان از کلاس طبقهبندی کننده جنگل تصادفی استفاده کرد.
جنگل تصادفی همزمان با رشد خود، درختان تصادفی بیشتری را به مجموعه اضافه میکند. در این بین نیز، به جای جستوجوی مهمترین ویژگی در حین تقسیم یک گره، بهترین ویژگی را در میان زیر مجموعهای تصادفی از ویژگیها جستوجو میکند. این عمل، منجر به تنوع گستردهای میشود که به طور کلی میتواند مدل بهتری را ارائه دهد. بنابراین، در جنگل تصادفی تنها یک زیر مجموعه تصادفی از ویژگیها، توسط الگوریتم تقسیم یک گره در نظر گرفته میشود. حتی میتوان درختها را با استفاده از آستانههای تصادفی برای هر ویژگی، به جای جستوجوی بهترین آستانههای ممکن، تصادفیتر کرد.
نحوه تشکیل و عملکرد جنگل تصادفی چیست؟
یک الگوریتم جنگل تصادفی از چندین درخت به نام درخت تصمیم (Decision Tree)، تشکیل شده است. جنگل تشکیل شده توسط الگوریتم جنگل تصادفی از طریق دستهبندی کیسهای یا (Bagging Classifier)، آموزش داده میشود. Bagging یک متا الگوریتم مجموعهای است که دقت الگوریتمهای یادگیری ماشین را افزایش میدهد.
جنگل تصادفی محدودیتهای الگوریتم درخت تصمیم را ندارد. این موضوع یکی از مزیتهای مهم این تکنیک یادگیری ماشینی است که در ادامه نیز در قسمت مزایای به کارگیری الگوریتم جنگل تصادفی چیست؟ بیشتر در مورد آن بحث خواهیم کرد. این الگوریتم، پردازش بیش از حد مجموعهی دادهها را کاهش داده و دقت را افزایش میدهد. همچنین پیشبینیها را بدون نیاز به تنظیمات خاصی در بستهها (مانند scikit_learn)، انجام میدهد.
Scikit Learn از کتابخانههای متنباز، مفید، پرکاربرد و قدرتمند در زبان برنامهنویسی پایتون است که برای اهداف یادگیری ماشین به کار میرود.
الگوریتم جنگل تصادفی چگونه کار میکند؟
درختان تصمیم در واقع بلوکهای اصلی سازندهی یک الگوریتم جنگل تصادفی هستند. درخت تصمیم نوعی درخت پشتیبانی است که ساختاری مانند درخت را تشکیل میدهد. آشنایی بیشتر با نحوهی شکلگیری درختان تصمیم، به ما کمک خواهد کرد تا بهتر بفهمیم الگوریتم جنگل تصادفی چگونه کار میکند. از این رو، در ادامه مطلب با اجزای درخت تصمیم بیشتر آشنا خواهیم شد.
اجزای درخت تصمیم چیست؟
درخت تصمیم از سه جزء تشکیل شده است؛ این سه قسمت عبارتاند از گره تصمیم، گره برگ و گرهی ریشه. الگوریتم درخت تصمیم، یک مجموعهی درخت آموزشی را به شاخههایی تقسیم میکند و این شاخهها هم خود به شاخههای دیگری تفکیک میشوند. این دنباله تا زمانی ادامه پیدا میکند که در نهایت، یک گرهی برگ حاصل شود. پس از تشکیل این گره، نمیتوان آن را به شاخههای بیشتری تبدیل کرد.
گرههای درخت تصمیم نشان میدهد که از برخی ویژگیهای موجود، میتوان برای پیشبینی نتیجه استفاده کرد. در نهایت، گرههای تصمیم نیز یک پیوند به برگها ارائه میدهند.
مزایای به کارگیری الگوریتم جنگل تصادفی چیست؟
مزایای به کارگیری تکنیک جنگل تصادفی، شامل موارد زیر است:
- الگوریتم جنگل تصادفی، نسبت به الگوریتم درختهای تصمیم بسیار دقیقتر و کاربردیتر است.
- این الگوریتم میتواند روشهای موثرتری را برای مدیریت دادههای از دست رفته ارائه دهد.
- الگوریتم جنگل تصادفی میتواند یک پیشبینی معقول، بدون نیاز به تنظیم بیش از حد پارامتر انجام دهد.
- جنگل تصادفی مشکل پردازش بیش از حد را در درختان تصمیم حل میکند.
- در هر درخت جنگل تصادفی، زیر مجموعهای از ویژگیها به طور تصادفی در نقطه تقسیم گره انتخاب میشوند.
تفاوتهای به کارگیری درخت تصمیم و جنگل تصادفی چیست؟
تفاوت اصلی بین الگوریتم درخت تصمیم و الگوریتم جنگل تصادفی این است که ایجاد گرههای ریشه و جداسازی گرهها به صورت تصادفی، در الگوریتم جنگل تصادفی انجام میشود. همچنین جنگل تصادفی از روش بستهبندی، برای ایجاد پیشبینی مورد نیاز استفاده میکند.
بستهبندی شامل استفاده از نمونههای مختلف داده (دادههای آموزشی)، به جای یک نمونه است. مجموعه آموزشی نیز شامل مشاهدات و ویژگیهایی است که برای پیشبینی استفاده میشود. درختان تصمیم، بسته به دادههای آموزشی تغذیه شده با الگوریتم جنگل تصادفی، خروجیهای مختلفی تولید میکنند. این خروجیها رتبهبندی میشوند و در نهایت بالاترین خروجی، به عنوان خروجی نهایی انتخاب میشود.
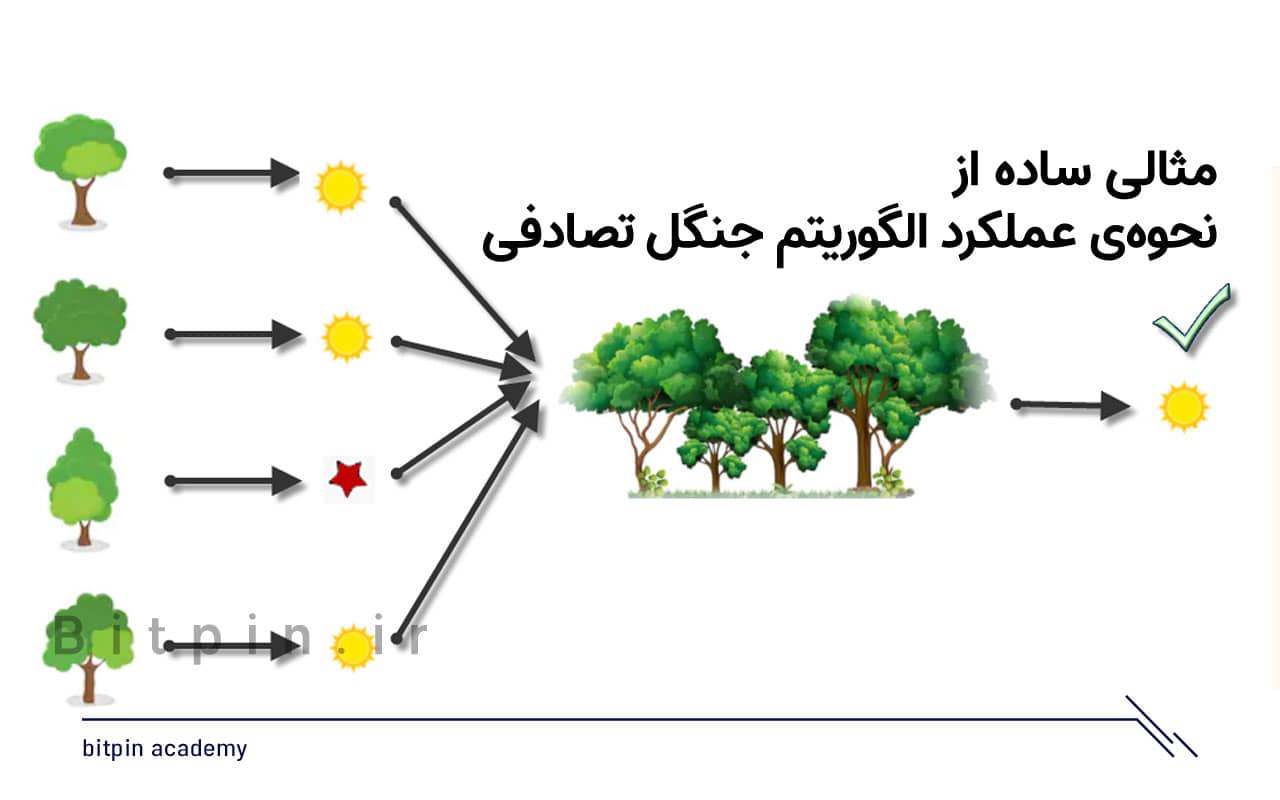
مثالی برای توضیح و تفهمیم کارکرد جنگلهای تصادفی
مثالی که در ادامه آمده است، توضیحی است که عملکرد جنگلهای تصادفی را به زبان سادهتر برای شما بیان میکند. در این عمل به جای داشتن یک درخت تصمیم واحد، یک جنگل تصادفی خواهد داشت که میتواند درختان تصمیم زیادی داشته باشد. در اینجا فرض میکنیم که فقط چهار درخت تصمیم داریم. در این حالت، دادههای آموزشی شامل مشاهدات و ویژگیهای گوشی یا تلفن همراه است که به چهار گره ریشه تقسیم میشود.
گرههای ریشه میتواند چهار ویژگی را نشان دهد که میتواند بر انتخاب مشتری تاثیر بگذارد. (برای مثال این چهار ویژگی برای گوشی عبارت است از: قیمت، حافظه داخلی، دوربین و رم). جنگل تصادفی، گرهها را با استفاده از انتخاب تصادفی ویژگیها، تقسیمبندی میکند. در آخر نیز پیشبینی نهایی، بر اساس نتیجهی چهار درخت اولیه انتخاب میشود.
نتیجهی انتخاب شده توسط اکثر درختان تصمیم، انتخاب نهایی خواهد بود. برای مثال اگر سه درخت، خرید را پیشبینی کند و یک درخت نخریدن را، پیشبینی نهایی “خرید” خواهد بود. و در این صورت پیشبینی میشود که مشتری، گوشی را بخرد.
اهمیت ویژگیهای جنگل تصادفی چیست؟
یکی از ویژگیهای عالی الگوریتم جنگل تصادفی این است که اندازهگیری اهمیت نسبی هر ویژگی، در زمان پیشبینی بسیار آسان است. Sklearn یک ابزاری عالی برای این کار ارائه میدهد. این ابزار میتواند با بررسی این که گرههای درختی که شامل یک ویژگی هستند، مشخص کند ناخالصی در میان همه درختان جنگل چقدر کاهش مییابد و اهمیت آن ویژگی را با دقت بالایی اندازهگیری کند. این امتیاز را به طور خودکار برای هر ویژگی، پس از آموزش محاسبه و نتایج به دست آمده را مقیاسه میکنند تا مجموع تمام اهمیتها، برابر یک باشد.
در این آزمایش هر شاخه، نشاندهندهی نتیجهی آزمایش است و هر گره برگ، نشاندهندهی یک برچسب کلاس است. با نگاه کردن به اهمیت هر ویژگی، میتوان بیان کرد که کدام ویژگیها احتمال حذف شدن دارند. زیرا آنها در فرایند پیشبینی نیز کارایی خوبی ندارند. البته باید توجه داشته باشید که هرچه مجموعهی شما ویژگیهای بیشتری داشته باشد، احتمال بیشتری وجود دارد که مدل شما از پردازش بیش از حد آسیب ببیند. در نتیجه، بهتر است تعادل را در انتخاب ویژگیهای مهم در نظر بگیرید.
نحوه طبقهبندی در جنگلهای تصادفی چگونه است؟
در طبقهبندی در جنگلهای تصادفی، از یک روش مجموع برای دستیابی به نتیجه استفاده میشود. سپس از دادههای آموزشی، برای تغذیهی درختهای تصمیمگیری مختلف مورد استفاده قرار میگیرد. این مجموعه داده شامل مشاهدات و ویژگیهایی است که در حین تقسیم گرهها، به طور تصادفی انتخاب شدهاند. یک سیستم جنگل بارانی، به درختان تصمیمگیری مختلف متکی است. همانطور که قبلا اشاره کردیم، هر درخت تصمیم از گره تصمیم، گره برگ و یک گره ریشه تشکیل شده است. گره برگ هر درخت، همان خروجی نهایی تولید شده توسط درخت تصمیم خاص است. انتخاب خروجی نهایی، از سیستم رای اکثریت پیروی میکند. در این حالت، خروجی انتخاب شده توسط اکثریت درختان تصمیم، به خروجی نهایی سیستم جنگل بارانی تبدیل میشود.
رگرسیون در جنگلهای تصادفی چیست؟
رگرسیون یکی دیگر از وظایفی است که توسط الگوریتم جنگل تصادفی انجام میشود. رگرسیون جنگل تصادفی، از مفهوم رگرسیون ساده پیروی میکند. مقادیر متغیرهای وابسته (ویژگیها) و مستقل نیز، در مدل جنگل تصادفی منتقل میشوند.
شما میتوانید رگرسیونهای تصادفی جنگل را در برنامههای مختلفی مانند R، SAS و python اجرا کنید. در رگرسیون یک جنگل تصادفی، هر درخت پیشبینی خاصی را تولید میکند. میانگین پیشبینی هر درخت، خروجی حاصل از رگرسیون است. البته این مدل، برخلاف اصول طبقهبندی جنگل تصادفی است که خروجی آن توسط حالت کلاس در درختان تصمیم، تعیین میشد. اگرچه رگرسیون جنگل تصادفی و رگرسیون خطی، از یک مفهوم پیروی میکنند، اما از نظر ریاضی و حالت آنها در تابع باهم تفاوت دارند. تابع رگرسیون خطی، y=bx+c است. اما عملکرد یک رگرسیون جنگل تصادفی، پیچیده و مانند جعبه سیاه است.
کاربردهای جنگل تصادفی در کسب و کارهای امروزی
برخی از کاربردهای جنگل تصادفی در کسب و کارهای پرطرفدار امروزی، میتواند شامل موارد زیر باشد:
- بانکداری
جنگل تصادفی در بانکداری، برای پیشبینی اعتبار متقاضی وام استفاده میشود. این سیستم به موسسهی وام دهنده کمک میکند تا در مورد دادن وام به مشتری یا خودداری از این کار، تصمیمگیری درستی داشته باشد. همچنین بانکها از الگوریتم جنگل تصادفی، برای شناسایی کلاهبرداران نیز استفاده میکنند.
- سلامت و مراقبتهای بهداشتی
متخصصان حوزهی بهداشت و سلامت از سیستم جنگل تصادفی برای تشخیص و دستهبندی بیماران استفاده میکنند. در واقع مشکلات بیماران با ارائهی سابقه پزشکی خود، تشخیص داده میشود. از سابقهی پزشکی بیماران در گذشته، برای تعیین مرحلهی بیماری، میزان پیشروی بهبودی و تعیین دوز داروهای مناسب استفاده میکنند.
- بازار سهام
تحلیلگران مالی از این سیستم، برای شناسایی بازارهای بالقوه و سودده در سهام استفاده میکنند. همچنین آنها میتوانند، رفتار سهام در بازار را نیز شناسایی کنند.
- تجارت الکترونیک
فروشندگان تجارت الکترونیکی میتوانند از طریق الگوریتمهای جنگل تصادفی، ترجیحات مشتریان خود را بر اساس رفتار مصرفشان در گذشته پیشبینی کنند.
چه زمانی لازم است از به کار بردن سیستم جنگل تصادفی اجتناب کنیم؟
استفاده از الگوریتمهای جنگل تصادفی در شرایط زیر ایدهآل نیستند:
- برون یابی
استفاده از رگرسیون تصادفی در برونیابی دادهها، ایدهآل نیست. برخلاف رگرسیون خطی که از مشاهدات موجود، برای تخمین مقادیر فراتر از محدوده مشاهده استفاده میکند، این سیستم توضیح میدهد که چرا بیشتر کاربردهای جنگل تصادفی، به طبقهبندی اختصاص مییابد.
- دادههای پراکنده
سیستم جنگلهای تصادفی، برای دادههایی که پراکندگی زیادی داشته باشند، نتایج خوبی به بار نمیآورد. در این حالت، زیرمجموعه ویژگیها و نمونههای بوت استرپ، یک فضای ثابت تولید میکنند. این عمل منجر به شکافهای غیر مولد میشود که بر نتیجهی کار نیز تاثیر میگذارد.
در بخشهای قبلی مزایای الگوریتم جنگل تصادفی را به صورت خاص بیان کردیم. در ادامه نوشتار قصد داریم مزایا و معایب این تکنیک را به عنوان جمعبندی بحث، یک بار دیگر بررسی کنیم.
بررسی مزایا و معایب جنگل تصادفی
با توجه به توضیحاتی که در این مقاله ارائه شد، مزایای الگوریتم جنگل تصادفی شامل موارد زیر است:
- جنگل تصادفی میتواند هر دو وظایف رگرسیون و طبقهبندی را انجام دهد.
- یک جنگل تصادفی، پیشبینیهای خوبی ارائه میدهد که به راحتی قابل درک است.
- این جنگل میتواند مجموعه دادههای بزرگ را نیز، به طور موثری اداره کند.
- الگوریتم جنگل تصادفی نسبت به درخت تصمیم نیز میتواند سطح بالاتری از دقت را ارائه میدهد.
- از دیگر مزیتهای مهم این سیستم، تطبیقپذیری آن است که میتوان از آن برای کارهای رگرسیون و طبقهبندی استفاده کرد.
- همچنین میتوان اهمیت نسبی که این الگوریتم به ورودیها میدهد، به راحتی مشاهده کرد.
اما معایب جنگل تصادفی شامل موارد زیر است:
- هنگام استفاده از یک جنگل تصادفی، منابع بیشتری برای محاسبه مورد نیاز است.
- این سیستم نسبت به الگوریتم درخت تصمیم، زمان بیشتری را مصرف میکند.
الگوریتم جنگل تصادفی، چگونه قیمت بیت کوین را پیشبینی میکنند؟
الگوریتم جنگل تصادفی
، در زمینههای مختلفی کاربرد دارد. برای اینکه به درک بهتری از نحوهی عملکرد الگوریتم رندوم فارست برسیم، استفاده از این الگوریتم را برای پیشبینی قیمت بیت کوین را با مثالی ساده بررسی میکنیم.
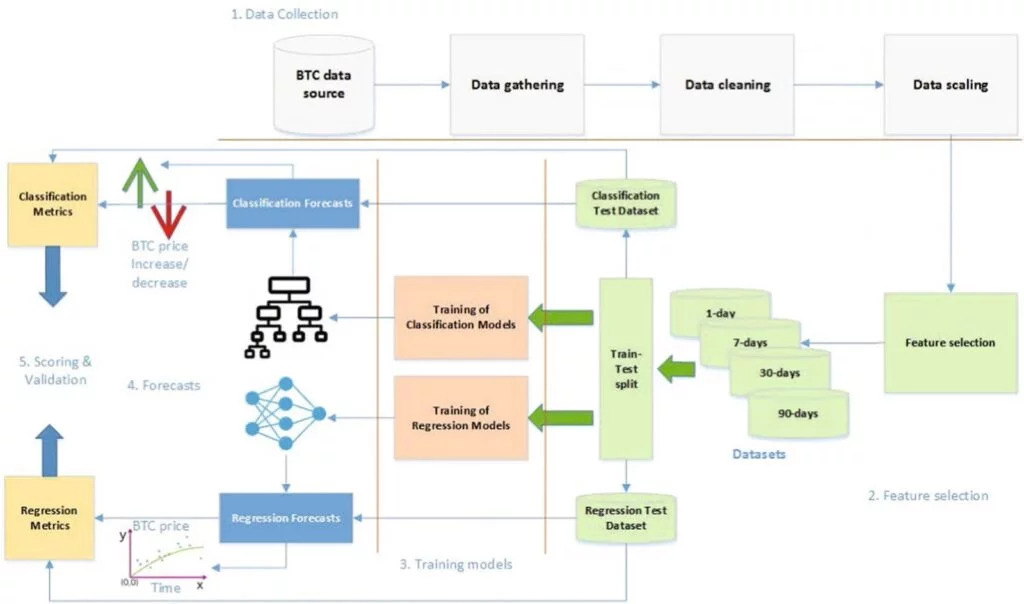
تصویر شماره 1
چارت بالا مسیر نحوهی پیشبینی قیمت بیت کوین را با کمک الگوریتم جنگل تصادفی نشان میدهد. این روند، شامل پنج مرحلهی جمعآوری دادهها، انتخاب ویژگیها، برآورد مدلها، پیشبینی و نهایی کردن و ارائهی نتیجه میشود.
در مرحلهی اول که مربوط به جمعآوری دادهها میشود، باید متغیرهایی را که قصد داریم برای پیشبینی قیمت بیت کوین استفاده کنیم، مشخص کنیم. این دادهها میتوانند قیمت شروع، بیشترین قیمت، کمترین قیمت، حجم مبادلات، قیمت پایانی و یا هر متغیر دیگری که مربوط به قیمت بیت کوین میشود، باشد. پس از جمعآوری و هماهنگسازی دادهها، نوبت به هممقیاسکردن دادهها (Data Scaling) میشود.
مجموعهای از دادهها بزرگ و مجموعهای بسیار کوچک هستند. با هممقیاسکردن دادهها، دامنهی اعداد در یک مقدار مشخص قرار خواهد گرفت.
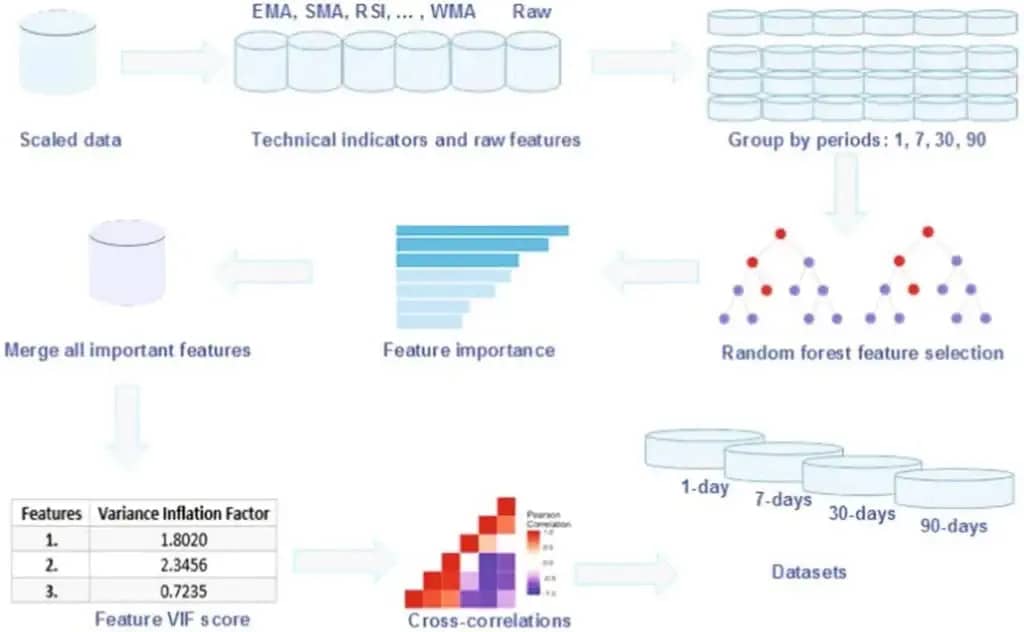
تصویر شماره 2
از مرحلهی هممقیاسکردن به بعد، الگوریتم رندوم فارست، فرآیند را آغاز میکند و به دستهبندی دادهها میپردازند. همانطور که در تصویر بالا میبینید، پس از دادههای هممقیاس شده، باید معیارها و ویژگیهای اندازهگیری را که قصد داریم به کار ببریم، معرفی کنیم.
بیش از 40 اندیکاتور مثل میانگین وزنی حجم قیمت (VWAP)، شاخص جریان پول (MFI)، میانگین متحرک ساده (SMA)، شاخص قدرت نصبی (RSI)، ابر ایچیموکو و بسیاری از موارد دیگر در تحلیل تکنیکال مورد کاربرد قرار میگیرد. علاوهبر آن، تایمفریمهای هر کدام از موارد نیز باید در نظر گرفته شود. برای مثال، میتوان از تایم فریمهای روزانه، هفتگی، سیروزه و 90 روزه استفاده کرد.
بعد از اینکه دادهها بر اساس زمان گروهبندی شدند، الگوریتم جنگل تصادفی شروع میشود. ویژگیها بر اساس میزان اهمیت، مرتب شده و پس از ادغام (Merge) براساس آزمون عامل تورم واریانس (Variance Inflation Factor)، رتبهبندی میشوند. این آزمون، شدت هم خطی میان متغیرهای مستقل را میسنجد. به بیان دیگر، به چه میزان هر کدام از متغیرهای مستقل نسبت به متغیرهای مستقل دیگر، تحت تاثیر قرار گرفته است؟!
در پایان، با بررسی همبستگی بین تمام متغیرها، دادههایی که از نظر ویژگی و درستی در محاسبه، عملکرد بهتری داشته باشند، بهعنوان گروه دادهها (Datasets)، در اختیار سیستم قرار میگیرد.
بعد از شکل گرفتن مجموعه دادهها، فرایند وارد فاز سوم میشود (باتوجه به تصویر شماره 1) و با توجه به دو مدل گروهبندی یا رگرسیونی، شروع به پیشبینی قیمت بیت کوین میکند. پس از پایان، دادههایی که به صورت خارج از کیسه، کنار گذاشته شده بودند، برای اینکه درستی و صحت برآورد را آزمایش کنند، در مدل به کار برده میشوند.
همانطور که در تصویر شمارهی 1 میبینید، در مدل رگرسیونی، خروجی در قالب یک نمودار و در مدل گروهبندی بهصورت افزایش یا کاهش، نمایش داده میشوند.
گفتار پایانی!
در این نوشتار بررسی کردیم که الگوریتم جنگل تصادفی چیست، چه اجزایی دارد و کاربردهای آن در حوزههای مختلف چگونه است. همانطور که اشاره شد، الگوریتم جنگل تصادفی یک الگوریتم یادگیری ماشینی است که استفاده از آن آسان و انعطافپذیر است. این سیستم از یادگیری مجموعهای استفاده میکند که با استفاده از آن، سازمانها میتوانند مشکلات رگرسیون و طبقهبندی را حل کنند.
جنگل تصادفی یک الگوریتم ایدهآل برای افرادی است که به دنبال توسعه و پیشرفت در کسب و کار خود هستند؛ زیرا مشکل بیش از حد پردازش مجموعهی دادهها را حل میکند. این الگوریتم یک ابزار بسیار کارآمد است که برای پیشبینیهای دقیق در تصمیمگیری استراتژیک سازمانها مورد استفاده قرار میگیرد. علاوهبر این موارد، از این الگوریتم در پیشبینی قیمت بیت کوین نیز استفاده میشود که نحوهی عملکرد آن را در بخش بالا با یک مثال ساده، بررسی کردیم.
سوالات متداول!
الگوریتم جنگل تصادفی چیست؟
یکی از تکنیکهای طبقهبندی برای حل مشکلات پیچیده الگوریتم جنگل تصادفی است.
مزایای الگوریتم جنگل تصادفی چیست؟
این الگوریتم دقت بسیار بالایی برای تحلیل مسائل دارد، گستره وسیعی از اطلاعات را میتواند در بر بگیرد و یکی از بهترین تکنیکهای حل مسائل پیچیده است.
